
La capacità umana di elaborare vaste quantità di informazioni visive è cruciale per raggiungere l’intelligenza artificiale generale (AGI). Nel corso degli anni, i ricercatori di intelligenza artificiale hanno sviluppato sistemi di Visual Question Answering (VQA) per interpretare scene all’interno di singole immagini e rispondere a domande correlate. Tuttavia, il VQA convenzionale è limitato all’interpretazione di singole immagini alla volta, anziché intere collezioni di dati visivi. Questo limite pone sfide in scenari più complessi come l’analisi di collezioni di immagini mediche, il monitoraggio della deforestazione tramite immagini satellitari, la mappatura dei cambiamenti urbani, l’analisi di elementi tematici in collezioni d’arte e la comprensione del comportamento dei consumatori da filmati di sorveglianza al dettaglio.
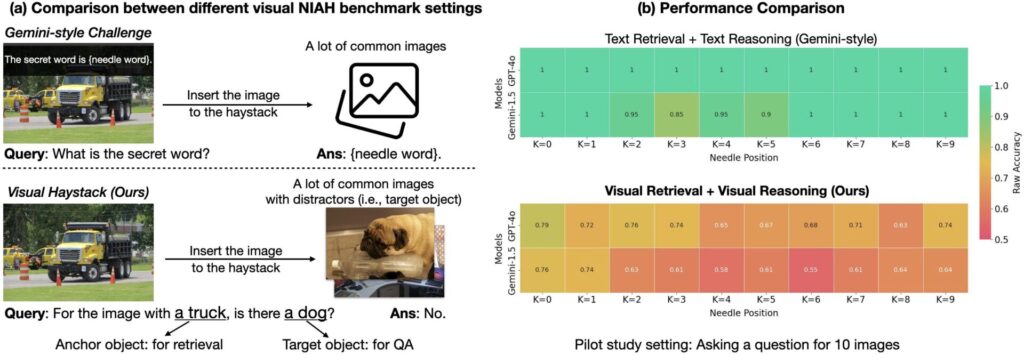
Per affrontare queste sfide, il progetto “Multi-Image Question Answering” (MIQA) va oltre i limiti dei tradizionali sistemi VQA, concentrandosi sull’elaborazione di informazioni visive attraverso grandi set di immagini non correlate.
Introduzione al Benchmark Visual Haystacks (VHs)
Il benchmark “Visual Haystacks” (VHs) è stato creato per valutare le capacità di ragionamento su contesti visivi estesi dei Large Multimodal Models (LMMs). Questo nuovo benchmark comprende circa 1.000 coppie di domande e risposte binarie, con ogni set contenente da 1 a 10.000 immagini. Le domande si concentrano sull’identificazione di contenuti visivi specifici, utilizzando immagini e annotazioni dal dataset COCO. Il benchmark VHs è suddiviso in due sfide principali:
- Single-Needle Challenge: Una singola immagine rilevante è nascosta tra molte altre. La domanda è formulata come: “Per l’immagine con l’oggetto ancora, c’è un oggetto target?”
- Multi-Needle Challenge: Da due a cinque immagini rilevanti sono nascoste nel set. Le domande possono essere: “Tutte le immagini con l’oggetto ancora contengono l’oggetto target?” o “Qualsiasi immagine con l’oggetto ancora contiene l’oggetto target?”
Principali Scoperte del Benchmark VHs
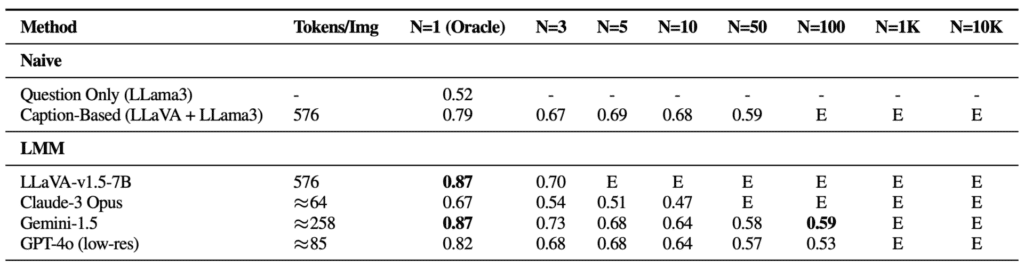
Il benchmark VHs ha rivelato tre sfide significative per gli attuali LMMs:
- Difficoltà con Distrattori Visivi: Nei contesti con un singolo ago, la performance dei modelli diminuisce significativamente man mano che aumenta il numero di immagini, indicando difficoltà nel filtrare informazioni visive irrilevanti.
- Difficoltà nel Ragionamento su Immagini Multiple: Nei contesti multi-ago, i metodi basati su LMM mostrano prestazioni deboli rispetto a approcci che utilizzano modelli di captioning seguiti da modelli di QA basati su linguaggio.
- Fenomeni nel Dominio Visivo: La precisione dei LMM è influenzata dalla posizione dell’immagine rilevante all’interno della sequenza di input, mostrando un fenomeno simile a “lost-in-the-middle” osservato nel campo della NLP.
Soluzione MIRAGE per Migliorare le Performance del VHs
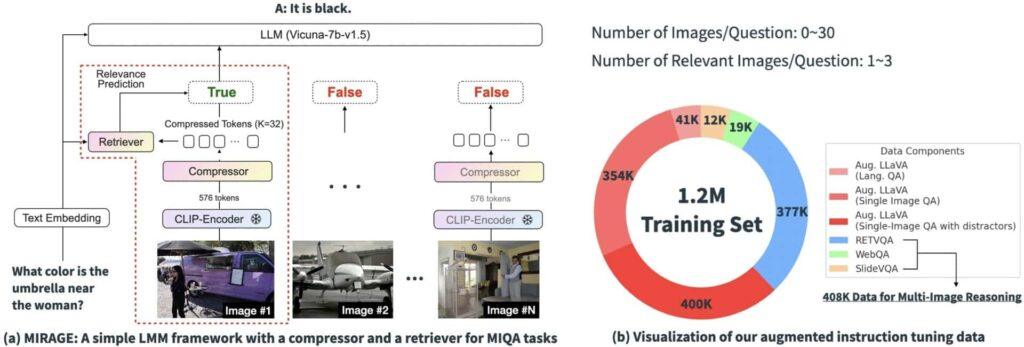
Per affrontare le sfide identificate, è stata proposta una nuova soluzione open-source chiamata “MIRAGE” (Multi-Image Retrieval Augmented Generation). Questo framework comprende:
- Compressione delle Codifiche Esistenti: Utilizzo di un modello di compressione consapevole delle query per ridurre i token dell’encoder visivo, consentendo di gestire più immagini nello stesso contesto.
- Utilizzo di un Retriever per Filtrare Messaggi Irrilevanti: Un retriever co-addestrato per predire la rilevanza delle immagini e scartare quelle irrilevanti.
- Dati di Addestramento Multi-immagine: Estensione dei dati di fine-tuning delle istruzioni su singola immagine con dati di ragionamento multi-immagine.
Risultati del Benchmark
MIRAGE ha dimostrato prestazioni all’avanguardia in molte delle sfide VHs, superando concorrenti come GPT-4, Gemini-v1.5 e LWM (Large World Model) nelle attività di QA su immagini multiple. Inoltre, il retriever co-addestrato di MIRAGE ha mostrato performance significativamente migliori rispetto a CLIP senza perdere efficienza.
Il benchmark Visual Haystacks e la soluzione MIRAGE rappresentano passi avanti significativi nella capacità di elaborare e ragionare su contesti visivi estesi. Questi strumenti offrono nuove opportunità per avanzare verso un’Intelligenza Artificiale Generale (AGI) più robusta e capace. La comunità è invitata a utilizzare il framework VHs per valutare e migliorare i propri modelli LMM prima della loro implementazione.