Inchieste
Ecco come Twisted Panda ha spiato la Difesa Russa
Tempo di lettura: 12 minuti. La Cina apprende in silenzio la tecnologia della Russia

In questo rapporto, i ricercatori di CPR hanno descritto ed esposto un’operazione di spionaggio cinese denominata Twisted Panda che prende di mira gli istituti di ricerca sulla difesa in Russia e forse anche in Bielorussia. Questa campagna si basa su tecniche di social engineering e sfrutta le sanzioni imposte di recente alla Russia per fornire una backdoor non documentata chiamata SPINNER a obiettivi specifici. Lo scopo della backdoor e dell’operazione è probabilmente quello di raccogliere informazioni da obiettivi all’interno dell’industria della difesa russa ad alta tecnologia per sostenere la Cina nel suo progresso tecnologico.
Si traduce il rapporto di Check Point Research:
Nell’ambito di questa indagine, abbiamo scoperto l’ondata precedente di questa campagna, anch’essa probabilmente rivolta a entità russe o collegate alla Russia, attiva almeno dal giugno 2021. L’evoluzione degli strumenti e delle tecniche in questo periodo di tempo indica che gli attori dietro la campagna sono persistenti nel raggiungere i loro obiettivi in modo furtivo. Inoltre, la campagna Twisted Panda dimostra ancora una volta la rapidità con cui gli attori dello spionaggio cinese si adattano e si adeguano agli eventi mondiali, utilizzando le esche più rilevanti e aggiornate per massimizzare le loro possibilità di successo.
Negli ultimi due mesi abbiamo osservato diversi gruppi APT che hanno cercato di sfruttare la guerra tra Russia e Ucraina come esca per operazioni di spionaggio. Non sorprende che le stesse entità russe siano diventate un obiettivo interessante per le campagne di spear-phishing che sfruttano le sanzioni imposte alla Russia dai Paesi occidentali. Queste sanzioni hanno esercitato un’enorme pressione sull’economia russa e in particolare sulle organizzazioni di diversi settori industriali russi.
Check Point Research (CPR) descrive una campagna mirata che ha utilizzato esche legate alle sanzioni per attaccare gli istituti di difesa russi, parte della Rostec Corporation. L’indagine dimostra che questa campagna fa parte di una più ampia operazione di spionaggio cinese in corso da diversi mesi contro entità legate alla Russia. I ricercatori di CPR ritengono con elevata sicurezza che la campagna sia stata condotta da un APT nazionale cinese esperto e sofisticato. Nel blog che segue, i ricercatori rivelano le tattiche e le tecniche utilizzate dagli attori della minaccia e forniscono un’analisi tecnica delle fasi e dei payload dannosi osservati, compresi loader e backdoor precedentemente sconosciuti con molteplici tecniche avanzate di evasione e anti-analisi.
Risultati principali:
Il CPR rivela una campagna mirata contro almeno due istituti di ricerca in Russia, la cui competenza principale è la ricerca e lo sviluppo di soluzioni di difesa altamente tecnologiche. La ricerca suggerisce che un altro obiettivo in Bielorussia, probabilmente anch’esso legato al settore della ricerca, ha ricevuto un’e-mail di spear-phishing simile, in cui si afferma che gli Stati Uniti starebbero diffondendo un’arma biologica.
Gli istituti di ricerca sulla difesa che abbiamo identificato come obiettivi di questo attacco appartengono a una holding del conglomerato statale russo della difesa Rostec Corporation. Si tratta della più grande holding russa nel settore della radioelettronica e gli istituti di ricerca presi di mira si occupano principalmente dello sviluppo e della produzione di sistemi di guerra elettronica, di apparecchiature radioelettroniche militari di bordo, di stazioni radar aeree e di mezzi di identificazione statale.
Questa campagna è la continuazione di quella che il CPR ritiene essere un’operazione di spionaggio di lunga durata contro entità legate alla Russia, in atto almeno dal giugno 2021. L’operazione potrebbe essere ancora in corso, dato che l’attività più recente è stata osservata nell’aprile 2022.
L’attività è stata attribuita con elevata sicurezza a un attore cinese, con possibili collegamenti a Stone Panda (alias APT10), un attore sofisticato ed esperto sostenuto da uno Stato nazionale, e a Mustang Panda, un altro attore esperto di spionaggio informatico basato in Cina. Il CPR ha chiamato questa campagna Twisted Panda per riflettere la sofisticazione degli strumenti osservati e l’attribuzione alla Cina.
Gli hacker utilizzano nuovi strumenti, che non sono stati descritti in precedenza: un sofisticato loader multilivello e una backdoor denominata SPINNER. Questi strumenti sono in fase di sviluppo almeno dal marzo 2021 e utilizzano tecniche avanzate di evasione e anti-analisi, come caricatori in-memory multistrato e offuscamenti a livello di compilatore.
Il 23 marzo sono state inviate e-mail dannose a diversi istituti di ricerca sulla difesa con sede in Russia. Le e-mail, che avevano come oggetto “Elenco di persone sottoposte a sanzioni statunitensi per l’invasione dell’Ucraina”, contenevano un link a un sito controllato dall’aggressore che imitava il Ministero della Salute della Russia minzdravros[.]com e contenevano in allegato un documento dannoso:
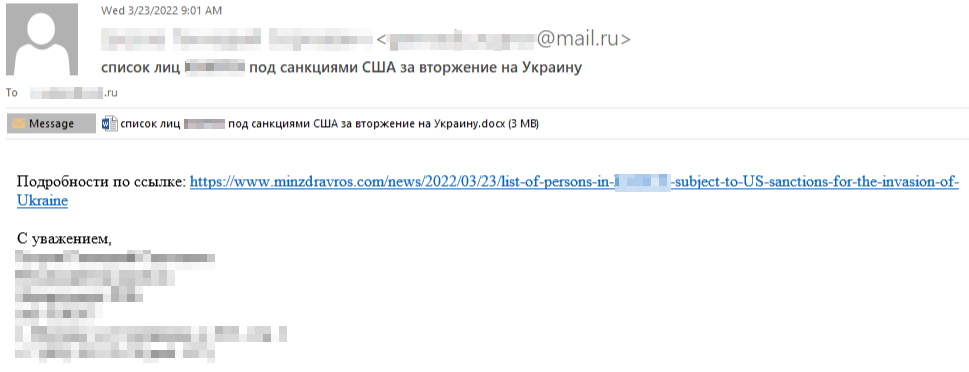
Figura 1: e-mail di spear-phishing inviata a istituti di ricerca in Russia.
Lo stesso giorno, un’e-mail simile è stata inviata anche a un’entità sconosciuta di Minsk, in Bielorussia, con l’oggetto “US Spread of Deadly Pathogens in Belarus”. Tutti i documenti allegati sono stati realizzati in modo da sembrare documenti ufficiali del Ministero della Salute russo, con tanto di emblema e titolo ufficiale:

Figura 2: Schermata del documento esca inviato agli istituti di ricerca in Russia.
Ogni documento scarica un modello esterno dagli URL con un formato simile, come https://www.microtreely.com/support/knowledgebase/article/AIUZGAE7230Z[.]dotm. Il modello esterno contiene un codice macro che importa diverse funzioni API da kernel32 (LoadLibraryA, CreateFileA, WriteFile, ReadFile, ecc.) e le utilizza per:
- Scrivere tre file (cmpbk32.dll, cmpbk64.dll e INIT) nel percorso: C:/Utenti/Pubblico.
- Caricare cmpbk32.dll o cmpbk64.dll (a seconda dell’architettura del sistema operativo) ed eseguire la funzione esportata R1.
L’esecuzione della funzione esportata R1 finalizza l’inizializzazione dei file dannosi. Il malware crea una directory di lavoro %TEMP%\OfficeInit e vi copia i file INIT e cmpbk32.dll, nonché un eseguibile legittimo di Windows a 32 bit cmdl32.exe dalla cartella System32 o SysWOW64, a seconda che il sistema operativo sia a 32 o 64 bit.
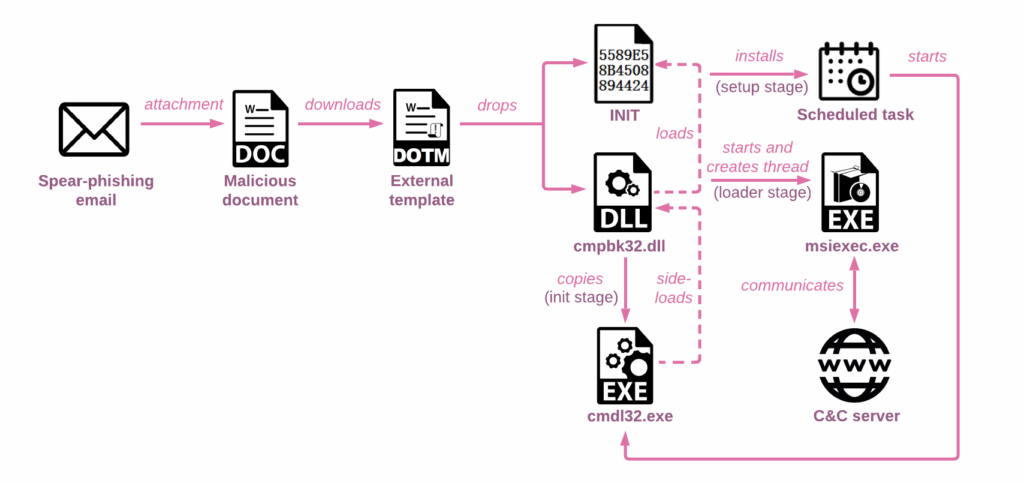
Figura 3: La catena di infezione semplificata.
Il Payload
Il payload è una DLL a 32 bit che utilizza la risoluzione dinamica delle API con hashing dei nomi per l’elusione e l’anti-analisi. Il caricatore non solo è in grado di nascondere la sua funzionalità principale, ma anche di evitare il rilevamento statico delle chiamate API sospette risolvendole dinamicamente invece di utilizzare importazioni statiche.
Lo scopo di cmpbk32.dll è quello di caricare uno shellcode specifico dal file INIT, a seconda dello stadio dell’infezione, ed eseguirlo. Il file INIT contiene due shellcode: lo shellcode del primo stadio esegue lo script di persistenza e pulizia, mentre lo shellcode del secondo stadio è un caricatore multilivello. L’obiettivo è decriptare consecutivamente gli altri tre livelli del caricatore senza file e caricare infine il payload principale in memoria. Per distinguere le fasi, il punto di ingresso della DLL DllMain esegue azioni diverse in base al motivo della chiamata.
Fase di impostazione
Quando il documento dannoso viene chiuso, viene attivato un evento PROCESS_DETACH. La DLL esegue una parte del file INIT incaricato di ripulire i file creati dal documento dannoso e crea un’attività pianificata per la persistenza:
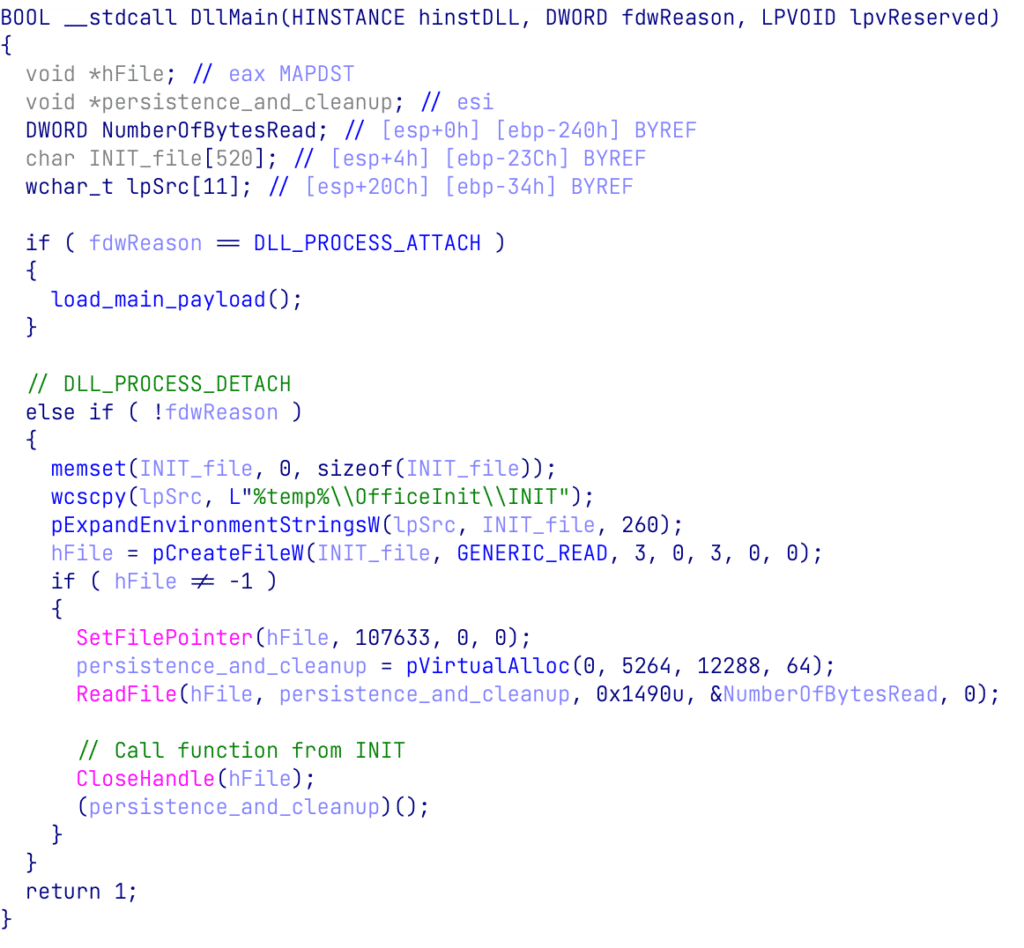
Figura 4: L’evento DLLMain PROCESS_DETACH esegue lo shellcode responsabile della persistenza e della pulizia da INIT.

Figura 5: funzione di persistenza e pulizia
Fase di caricamento
Il processo di caricamento principale inizia con l’esecuzione dell’attività pianificata cmdl32.exe che carica la DLL dannosa cmpbk32.dll. Il sideloading della DLL da parte di un processo legittimo è una tecnica comunemente utilizzata dagli attori delle minacce; l’accoppiamento con un processo di caricamento robusto può aiutare a eludere le moderne soluzioni antivirus poiché, in questo caso, l’effettivo processo in esecuzione è valido e firmato da Microsoft. Si noti che il file cmpbk64.dll non viene copiato nella cartella %TEMP%\OfficeInit. La versione a 64 bit della DLL viene utilizzata solo nella fase iniziale dell’infezione dal processo MS Word a 64 bit, poiché cmdl32.exe a 32 bit può caricare solo cmpbk32.dll a 32 bit.
Quando la DLL viene caricata, viene attivato l’evento PROCESS_ATTACH che avvia una sequenza di operazioni. La sequenza elimina diversi livelli crittografati dal file INIT e alla fine rivela ed esegue il payload finale. Per prima cosa legge un blob crittografato con XOR dal file INIT e lo decrittografa in memoria utilizzando un semplice XOR con la chiave 0x9229. Il blob decrittografato è un codice indipendente dalla posizione e il primo dei livelli crittografati che “proteggono” il payload principale.
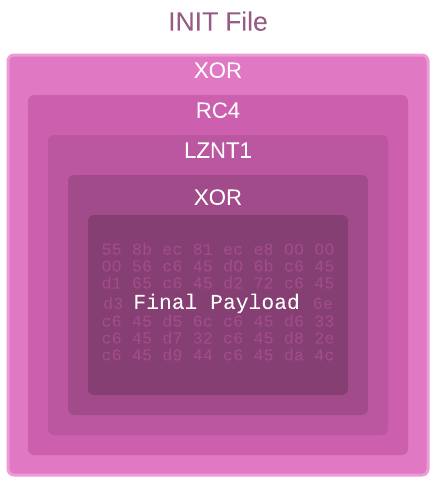
Figura 6: Livelli di decodifica eseguiti dal caricatore per scoprire il payload finale.
Questo primo livello è piuttosto semplice. Carica dinamicamente da Kernel32.dll le funzioni WinAPI essenziali per il suo lavoro. Successivamente, inizia una sequenza di operazioni per scoprire il secondo livello. Utilizza RC4 con la seguente chiave codificata: 0x1C, 0x2C, 0x66, 0x7C, 0x11, 0xCF, 0xE9, 0x7A, 0x99, 0x8B, 0xA3, 0x48, 0xC2, 0x03, 0x07, 0x55. Quindi decomprime il buffer decriptato utilizzando RtlDecompressBuffer e rivela il secondo livello.

Figura 7: Iniezione in msiexec.exe
Il codice iniettato inizia caricando dinamicamente un file PE incorporato all’interno ed eseguendolo dal suo punto di ingresso.
La backdoor SPINNER: analisi tecnica
Il payload utilizza due offuscamenti a livello di compilatore:
Appiattimento del flusso di controllo: altera il flusso di codice rendendolo non lineare.
Predicati opachi: definisce la logica inutilizzata e fa sì che il binario esegua calcoli inutili.
Entrambi i metodi rendono difficile l’analisi del payload, ma insieme rendono l’analisi dolorosa, lunga e noiosa. Questi due tipi di offuscamento sono stati precedentemente individuati come utilizzati insieme in campioni attribuiti al gruppo di lingua cinese Stone Panda (APT10) e Mustang Panda.

Figura 8: offuscamento del codice con predicati opachi e appiattimento del flusso di controllo nel campione SPINNER.
Quando la backdoor SPINNER inizia a funzionare, crea un mutex chiamato MSR__112 per garantire che ci sia una sola istanza del payload in esecuzione alla volta. Il payload espande anche la persistenza precedentemente creata dal caricatore. Crea una nuova chiave del Registro di sistema OfficeInit in SOFTWARE\Microsoft\Windows\CurrentVersion\Run che punta al percorso cmdl32.exe.
Quindi, imposta la propria configurazione, che contiene i seguenti campi:
struct malware_config {
std::string full_c2_url;
std::string host_name;
std::string c2_uri;
DWORD use_https;
DWORD port;
DWORD sleep_time;
}Il full_c2_url viene decifrato utilizzando la decifrazione XOR con la chiave 0x50. Dopo la decrittazione, la funzione InternetCrackUrlA viene utilizzata per decifrare un URL nei suoi componenti: i campi c2_url_without_scheme, c2_uri, port e use_https.
Successivamente, la backdoor inizia il suo ciclo principale controllando se è la prima esecuzione e quindi non è ancora avvenuto il fingerprinting del sistema. Se la risposta è negativa, la backdoor crea un ID Bot casuale di 16 byte e lo salva nel file %TEMP%\OfficeInit\init.ini. Quindi raccoglie dati sul sistema infetto e crea una stringa contenente i seguenti dati:
- ID bot
- Nome del computer
- IP locale
- Versione di Windows
- Nome utente
- Tempo di riposo recuperato dalla configurazione del malware
- ID processo
- NULL aggiunto alla fine della stringa
Campagna precedente
Durante la ricerca su VirusTotal di file simili al loader, abbiamo riscontrato un ulteriore cluster che utilizza il sideloading di DLL per lanciare un loader in-memory molto simile a quello discusso in precedenza. Carica quindi un payload che potrebbe essere una variante precedente della backdoor SPINNER. A giudicare dai nomi dei file e dai timbri di compilazione degli eseguibili, la campagna è attiva dal giugno 2021.
A differenza dell’attuale campagna, che utilizza documenti Microsoft Word come dropper, la precedente ondata di attacchi si basava su file eseguibili con il logo di Microsoft Word. Ciò suggerisce che questi dropper erano destinati a essere consegnati alle vittime con gli stessi mezzi dei documenti dannosi, tramite e-mail di spear-phishing, sia come allegati che come link a siti falsi.
Evoluzione dei TTP della campagna
In meno di un anno, gli attori hanno migliorato significativamente la catena di infezione e l’hanno resa più complessa. Tutte le funzionalità della vecchia campagna sono state conservate, ma sono state suddivise tra più componenti, rendendo più difficile l’analisi o il rilevamento di ogni fase. Ecco alcuni esempi di componenti suddivisi:
La funzionalità del dropper EXE è suddivisa tra un documento dannoso e il payload. È un adattamento ragionevole come eseguibile. Anche uno che si maschera da documento potrebbe destare molti più sospetti di un documento accuratamente realizzato.
Aggiunta di ulteriori funzionalità al caricatore di DLL. È interessante notare che gli attori hanno scelto di non aggiungere altre funzioni esportate alla DLL, ma di gestire diversi motivi di chiamata in DllMain, facendo in modo che alcune parti di codice dannoso vengano eseguite in background quando il documento viene chiuso.
Sebbene il caricatore contenga alcune tecniche di anti-analisi e di evasione, come l’uso di shellcode e la risoluzione dinamica delle API tramite hashed, nell’ultima campagna gli attori hanno aggiunto miglioramenti significativi integrando complesse offuscazioni a livello di compilatore alla backdoor SPINNER.
Oltre alle complesse offuscazioni, la backdoor SPINNER è stata ridotta alle sole funzionalità di base. Questo è stato fatto probabilmente per aumentare la furtività e l’evasione del malware.
Attribuzione
Backdoor SPINNER
Come per qualsiasi campione di malware sconosciuto, l’analisi del loader e della backdoor di SPINNER ha richiesto l’RCP per determinare se si trattasse di un campione di malware noto o di una famiglia di malware completamente nuova. A prima vista, il payload sembrava simile al malware PlugX/Hodur descritto da ESET in un rapporto recentemente pubblicato sull’APT cinese Mustang Panda. La prima somiglianza riguarda la numerazione ID dei comandi C&C: entrambi i malware utilizzano 2 byte per specificare la categoria di comando e 2 byte per un comando specifico di questa categoria. Ad esempio, il comando 0x10010001 viene utilizzato nella variante SPINNER per inviare i dati delle informazioni di sistema, mentre il malware Hodur utilizza il gruppo di comandi 0x1001 e l’ID del comando 0x1001 per la stessa azione.
Inoltre, alcuni dei comandi stessi si sovrappongono tra i campioni, come quelli che elencano le unità logiche, ottengono informazioni dettagliate sui file in una directory o eseguono comandi utilizzando cmd.exe. Queste funzionalità non sono uniche e di solito si trovano in molte backdoor. In questo caso, i due malware condividono una somiglianza ancora più grande e sorprendente. Dopo aver aperto la variante Hodur PlugX nel disassemblatore, è emerso che Hodur, come SPINNER, è stato pesantemente offuscato utilizzando il Control Flow Flattening (CFF). Tuttavia, il CFF di Hodur è diverso da quello di SPINNER. Il CFF di Hodur si basa su un dispatcher che utilizza un determinato registro per decidere a quale blocco di codice saltare successivamente, mentre in SPINNER il registro viene utilizzato così com’è senza alcuna manipolazione. Nella variante PlugX, vengono utilizzate operazioni aritmetiche aggiuntive sul registro prima che venga controllato dal dispatcher. Per completare il confronto con l’offuscamento, Hodur offusca pesantemente le chiamate API e le stringhe, un passaggio assente in SPINNER.
In termini di implementazione, i campioni di malware sono completamente diversi. Hodur è un’applicazione desktop di Windows multithread e comunica con il C&C attraverso più thread, ognuno con il proprio scopo, mentre SPINNER è un’applicazione console a thread singolo. Il metodo di enumerazione di Hodur è più esteso di quello di SPINNER, ma non utilizza il Bot ID che identifica una specifica macchina infetta. La funzione di autocancellazione di Hodur potrebbe essere simile nella sua logica a quella di SPINNER, ma utilizza una serie di comandi completamente diversi per eliminare se stesso e i file associati. La logica di comunicazione di Hodur con il C&C è più complessa e proviene da diverse parti del codice e da più thread, mentre SPINNER ha una sola funzione che gestisce i comandi.
Sebbene le differenze indichino l’appartenenza di questi malware a famiglie diverse, essi condividono delle similitudini di “best practice“. Ecco alcuni esempi di somiglianze:
- Entrambi utilizzano le funzioni WS2_32 per recuperare l’indirizzo IPv4 del computer locale.
- Mostrano interesse nell’enumerazione dei file in determinate directory, cercando dati specifici come l’ora dell’ultimo accesso
- Entrambi enumerano le unità disco, ricercando i thumb drive alla ricerca di dati interessanti
- Eseguono comandi dal C&C tramite cmd.exe utilizzando una pipe, ecc.
- Si può sostenere che queste sono solo tecniche comuni utilizzate da tutte le backdoor, ma non è improbabile che questi strumenti possano avere la stessa fonte a monte e quindi condividere molte best practice e metodi.
Attività basata sulla Cina
Le tattiche, le tecniche e le procedure (TTP) di questa operazione ci hanno permesso di attribuirla a un’attività APT cinese. In generale, i gruppi cinesi sono noti per il riutilizzo e la condivisione di strumenti. In assenza di prove sufficientemente solide, come connessioni basate sull’infrastruttura, non abbiamo potuto attribuire direttamente questa attività con elevata sicurezza a uno specifico attore cinese della minaccia. Tuttavia, la campagna Twisted Panda presenta numerose sovrapposizioni con attori cinesi di cyber-spionaggio avanzati e di lunga data:
Le offuscazioni dei flussi di controllo osservate in SPINNER sono state precedentemente utilizzate dal gruppo cinese APT10 e sono riapparse in una recente campagna di spionaggio di Mustang Panda:
Il gruppo APT Mustang Panda è stato osservato sfruttare l’invasione dell’Ucraina per colpire entità russe nello stesso periodo di Twisted Panda.
Il flusso di infezione che si basa sul side-loading delle DLL è una tecnica di evasione preferita utilizzata da diversi attori cinesi. Tra gli esempi vi sono il famigerato malware PlugX (e le sue molteplici varianti, tra cui i già citati campioni di Mustang Panda’ Hodur), la campagna di spionaggio globale APT10 pubblicata di recente che utilizzava il lettore VLC per il side-loading e altre campagne APT10.
Oltre alle somiglianze tra SPINNER e Hodur che abbiamo menzionato in precedenza, anche altre pratiche come i caricatori in-memory multistrato basati su shellcode e PE, specialmente combinati con risoluzioni API dinamiche tramite hash, sono una tecnica tipica di molti gruppi cinesi. La vittimologia della campagna Twisted Panda è coerente con gli interessi cinesi a lungo termine.
Gli obiettivi
Gli istituti di ricerca sulla difesa che abbiamo identificato come obiettivi di questo attacco appartengono a una holding del conglomerato statale russo della difesa Rostec Corporation. Si tratta della più grande holding russa nel settore della radioelettronica e gli istituti di ricerca presi di mira si occupano principalmente dello sviluppo e della produzione di sistemi di guerra elettronica, di apparecchiature radioelettroniche militari di bordo, di stazioni radar aeree e di mezzi di identificazione statale. Gli enti di ricerca si occupano anche di sistemi avionici per l’aviazione civile, dello sviluppo di una serie di prodotti civili come le apparecchiature mediche e di sistemi di controllo per l’energia, i trasporti e le industrie ingegneristiche.
Il piano Made in China 2025 definisce gli obiettivi della Cina per diventare una grande potenza tecnologica ed economica e identifica anche i settori in cui deve diventare leader mondiale, tra cui la robotica, le apparecchiature mediche e l’aviazione. A sostegno di ciò, il piano quinquennale cinese per il periodo 2021-2025 prevede un aumento costante dei budget per la ricerca e lo sviluppo al fine di espandere le capacità scientifiche e tecniche della Cina. Tuttavia, molteplici rapporti, non provenienti dagli Stati Uniti e da altri Paesi, tra cui la Russia, considerata partner strategico della Cina rivelano che, accanto alle relazioni e alle misure palesi, la Cina impiega strumenti occulti per raccogliere informazioni, combinando così le partnership con diverse attività di spionaggio. Insieme alle precedenti segnalazioni di gruppi APT cinesi che conducono le loro operazioni di spionaggio contro il settore governativo e della difesa russo, la campagna Twisted Panda descritta in questa ricerca potrebbe servire come ulteriore prova dell’uso dello spionaggio in uno sforzo sistematico e a lungo termine per raggiungere gli obiettivi strategici cinesi in termini di superiorità tecnologica e potenza militare.










Inchieste
Perchè il motore di ricerca OpenAI fa paura ai giornalisti?
Tempo di lettura: 4 minuti. OpenAI sfida Google con un nuovo motore di ricerca basato su ChatGPT, promettendo un’evoluzione nella ricerca online.

OpenAI sembra pronta a rivoluzionare il mondo della ricerca online lanciando un proprio motore di ricerca basato su ChatGPT, secondo quanto riportato da diverse fonti autorevoli. Il lancio di questo nuovo servizio è previsto per il 9 maggio e potrebbe segnare una svolta significativa nel modo in cui le informazioni vengono cercate e trovate su Internet secondo molti addetti ai lavori dell’informazione tecnologica, ignari che questo cambiamento sia già in corso.
Dettagli del lancio
Il nuovo motore di ricerca, indicato con il dominio https://search.chatgpt.com, è al centro di numerose discussioni e speculazioni. Il CEO di OpenAI, Sam Altman, ha espresso in più occasioni l’intenzione di integrare i modelli linguistici avanzati (Large Language Models) nella ricerca web, proponendo un’alternativa all’approccio tradizionale di Google che presenta pagine di risultati piene di annunci e link.
Implicazioni di Mercato
Google, che domina il mercato dei motori di ricerca con una quota vicina al 90%, potrebbe trovarsi di fronte a una nuova concorrenza significativa. Non solo, Microsoft, uno dei principali finanziatori di OpenAI, potrebbe vedersi in una posizione complicata se OpenAI decidesse di competere direttamente con Bing, il suo motore di ricerca. Oppure il motore di ricerca firmato ChatGPT è il fumo negli occhi per evitare maggiori attenzioni delle indagini concorrenziali dei vari garanti del mercato in giro per il mondo?
Collaborazioni e competizioni
Anche Apple è menzionata come un possibile collaboratore di OpenAI, intensificando le trattative per integrare ChatGPT nei dispositivi iOS. Tuttavia, ciò potrebbe complicare le relazioni tra Apple e Google, che paga miliardi ogni anno per rimanere il motore di ricerca predefinito su dispositivi iOS.
Aspetti tecnologici e innovativi
Il motore di ricerca di OpenAI promette di utilizzare l’intelligenza artificiale per migliorare l’esperienza di ricerca degli utenti, fornendo risposte più contestualizzate e precise, sfruttando le capacità uniche dei modelli generativi di linguaggio. Il lancio del motore di ricerca di OpenAI rappresenta non solo un’evoluzione tecnologica significativa ma anche un potenziale cambio di paradigma nel settore dei motori di ricerca. Le implicazioni di questa mossa sono vastissime, influenzando non solo le aziende tecnologiche ma anche gli utenti e il modo in cui accedono alle informazioni online.
Google deve preoccuparsi?
Al netto delle notizie che annunciano il nuovo motore di ricerca realizzato da OpenAI, gli acchiappa clic dell’informazione italica hanno intitolato che ad aver paura di questa iniziativa imprenditoriale di nuova generazione debba essere Google, da anni motore di ricerca, incontrastato con un monopolio di fatto nonostante ci siano diversi alternative e l’Europa stia andando verso una direzione rappresentativa dell’intero mercato. Seppur un nuovo competitor, con una tecnologia proprietaria all’avanguardia rispetto a tutto il resto del mercato, rappresenti una preoccupazione per il grande burattinaio della rete, a doversi preoccupare in realtà sono tutti gli attori impegnati oggi per pochi spiccioli a fornire contenuti alla materia oscura di Google. Questa preoccupazione, ad oggi, è comunque parte di un colosso che sta già agendo in questa direzione ed è possibile notarlo attraverso gli aggiornamenti oramai a cadenza semestrale che BIG sta facendo sottoforma di reindicizzazione della rete Internet.
Non è data sapere la metodica ed i criteri dell’algoritmo con cui Google sta provvedendo Nel riscrivere le regole della ricerca su Internet, ma tutti i siti Internet, a parte quelli inviso alla cupola della sezione News, stanno subendo dei cali vertiginosi proprio dagli indici di ricerca. Se Google nel suo ultimo aggiornamento si è concentrato nell’arginare i contenuti di intelligenza artificiale generati solo ed esclusivamente per imbrogliare l’algoritmo con il fine di indicizzare siti di cucina insieme a quelli di tecnologia per esempio, oggi sta iniziando a fornire direttamente le risposte e tutto questo va in danno ai link dei siti Internet che pubblicano le informazioni.
Davvero chi oggi descrive l’avvento del motori di ricerca di OpenAI in realtà non ha ancora compreso che tutto questo andrà a penalizzare un intero settore che non è più ristretto ai Media, ma all’intera generazione di contenuti su Internet?
Il fatto che le risposte generate da Google, seppur citino la fonte, fanno perdere tanto traffico ai siti dal punto di vista della ricerca organica, soprattutto in un’epoca dove l’utente è abituato a non approfondire, bensì a leggere velocemente soffermandosi sulle prime risposte senza avvertire la necessità di approfondire nel link d’origine.
Con ChatGPT ed il suo motore di ricerca questo procedimento si amplificherà di più a maggior ragione del fatto che la sua tecnologia è criticata proprio per essere irriconoscente nei confronti di coloro che generano contenuti e che li utilizza impropriamente per addestrare la il suo modello linguistico avanzato. Se Google ha dato, e sta dando, una mazzata notevole alla rete, OpenAI rischia di dare un colpo di grazia definitivo a tutti coloro che quotidianamente forniscono risposte ed informazioni ai quesiti degli utenti della rete mantenendoli aggiornati con il corso del tempo.
Il paradosso del Click
Quindi assistiamo al fatto che per catturare un singolo clic, le testate editoriali fanno riferimento alla paura di Google ignorando quei rischi che in realtà potrebbero definitivamente gli potrebbe far perdere clic e visualizzazioni in futuro difficili più di quanto stia avvenendo ora, sacrificando visualizzazioni ed in introiti pubblicitari. Non è un caso che la Commissione Editoria voluta dal governo abbia promosso un equo compenso per gli editori che verranno surclassati dalla tecnologia dell’intelligenza artificiale applicata nella generazione di informazioni e di risposte fornite dai motori di ricerca già alimentata da colossi del settore che intendono effettuare un passaggio strutturale definitivo concentrato all’impiego di contenuti generati attraverso applicativi di intelligenza artificiale.
E mentre la cupola dei grandi gruppi editoriali è stata garantita dall’immagine divina di padre Paolo Benanti e del curatore degli interessi della famiglia Berlusconi padre Alberto Barachini, sottosegretario all’editoria, se Google debba iniziare a preoccuparsi, lo sa bene anche la stessa Microsoft che si nasconde dietro ai progetti di OpenAI che stanno decretando una crescita improvvisa e smisurata della sua offerta tecnologica, ma ad essere a rischio non solo è la proprietà intellettuale, ma tutto un sistema di informazione che ovviamente assottiglia sempre di più la sua visibilità in un mercato che è tutt’altro che libero e che non offre le stesse possibilità di crescita: sempre che non si riesca a far parte della cupola di Governo in combutta con Google News ed altre realtà come le piattaforme social.
Inchieste
Ransomware in Italia: come cambia la percezione del fenomeno nell’IT
Tempo di lettura: 5 minuti. I ransowmare sembrano essere passati di moda per il poco clamore suscitato in un paese come l’Italia dove interessano solo a una nicchia

Cosa sta accadendo al mondo della sicurezza informatica ed al suo rapporto con i ransomware in Italia?
I temuti attacchi informatici che criptano server e computer, bloccandone i servizi, e chiedono un riscatto per sbloccarli altrimenti vengono diffusi in rete, pericolosissimi aziende privati, professionisti, Enti ed istituzioni di Governo, sembrano essere diventati un fenomeno da barraccone per i feticisti della cybersecurity.
Ransomware e l’Italia: un feticcio per pochi
L’Italia rappresenta una nicchia di mercato soprattutto perché ha una sua identità linguistica. L’argomento della cybersecurity nel nostro paese è collegato per motivi di opportunità allo scenario internazionale ed ai tecnicismi anglosassoni che ne hanno forgiato termini ed applicazioni tecniche sul campo. Sono molti i progetti editoriali che parlano del fenomeno della sicurezza informatica, ma sono pochi quelli indipendenti e che coinvolgono una nicchia composta da esperti del settore informatico e dai grossi media che per sopravvivere alle regole di un mercato sempre più chiuso dagli algoritmi, sfruttano il proprio blasone per affrontare marginalmente il problema. Matrice Digitale parla di questa tematica dal 2017 con oltre 3.500 articoli di settore pubblicati in lingua italiana a cui si dovrebbero aggiungere i mille video sul canale YouTube, prima chiuso dalla piattaforma e poi riaperto dopo 3 anni di lotta: una scelta suicida nel panorama d’interesse italico per chi è indipendente da associazioni o cooperative non ufficiali di aziende ed Enti che fanno affari, o lobbying, sul tema. Il caso della piattaforma open source Ransomfeed, un valido progetto ingegneristico di raccolta statistica degli attacchi ransomware sviluppato in italiano e trasformato in lingua inglese, dimostra che per avere autorevolezza e considerazione nel contesto cyber, bisogna guardare oltre i confini del Bel Paese.
L’attacco informatico è “normale”
Oltre al clamore dei vari attacchi, identificati con diversi nomi e sigle di malware e gruppi criminali, qui gli articoli di Matrice Digitale sul tema, che hanno causato dei blocchi alle catene produttive delle più grandi aziende del paese e la fuga dei dati delle aziende sanitarie locali, il fenomeno sembrerebbe essere diventato un ricorrente e superficiale. Perché alla base di tutto c’è la regola universale secondo la quale è impossibile avere la matematica certezza di non essere colpiti da un attacco informatico ed è su questo principio, leit motiv degli addetti del mondo della sicurezza informatica, che il ransomware è stato normalizzato nell’immaginario collettivo di quella vulgata che ogni giorno è a rischio attacco informatico sia sul lavoro sia tra le mura domestiche. Un altro aspetto da non sottovalutare è proprio il fatto che la grande diffusione del fenomeno ha portato le agenzie internazionali di sicurezza informatica, che rispondono ai Governi, ad intimare alle aziende di non effettuare il pagamento del riscatto previsto dal metodo criminale di attacco. Seppur il cedere economicamente rappresenti un grande male nel rapporto tra guardie e ladri, sono in calo a livello globale i pagamenti dei riscatti ed il non pagare ha portato le gangs ad agire in modo ancor più infame, perché ha aumentato l’asticella etica dei propri attacchi sferrandoli su settori solitamente tutelati dal codice deontologico criminale come ad esempio i dati dei minori e quelli sanitari, a maggior ragione di pazienti oncologici.
Considerazione maligna di chi scrive: normalizzare il fenomeno è anche un’opportunità per i tecnici e le Istituzioni preposte nel mettere le mani avanti ad eventuali falle nella gestione dei dati dei clienti ed alle aziende di sottrarsi alla scomoda domanda se hanno pagato o meno il riscatto.
Il ransomware è un fenomeno che necessita soluzione o risposta?
L’attacco ransomware non solo è visto come una probabilità sempre più certa , ma il valore del dato diventa sempre meno considerato perché la maggior parte dei dati personali di tutti i cittadini connessi ad Internet, e non solo come nel caso dei nascituri canadesi, sono già esposti in rete . Questa esposizione ha portato delle tattiche criminali parallele dove si allestiti dei call center che contattano gli utenti esposti e si chiedono delle informazioni per aggiornare quelli che sono i dati in proprio possesso appartenenti evidentemente a dei database trafugati negli anni passati e che ad oggi contengono delle informazioni che non sono più attuali. Così come dopo il devastante data leak e data breach di WhatsApp, Facebook, che ha esposto quasi un miliardo di persone, ci siamo trovati delle campagne mirate sulle app di messaggistica dove venivano implementate tattiche di ingegneria sociale finalizzate ad ottenere ulteriori dati o pagamenti che hanno aumentato le statistiche delle truffe informatiche in rete. Andrea Lisi a Matrice Digitale ha parlato di circolazione del dato e non più del suo valore anche per questo motivo.
Il caso SynLab e la differenza tra prevenzione e risposta
Il recente attacco informatico che ha colpito la società Synlab Italia, rivendicato in queste ore dalla gang BlackBasta, e che ha messo giù per diverse settimane i laboratori di analisi e di diagnostica della multinazionale, esponendo dati personali sanitari e sensibili di una buona fetta del territorio italiano, ha certificato il disinteresse verso il ransomware in sè, ma ne ha amplificato un altro che sembrerebbe essere lo snodo cruciale dell’evoluzione mediatica degli attacchi informatici e che coinvolge la necessità di una maggiore capacità di risposta a questi ultimi. Il problema oggi sembrerebbe non essere più perdere il dato, che comunque comporta delle multe e delle sanzioni da parte del Garante, ma è per forza di cose il ripristinare quanto prima i servizi che incidono da subito sulle attività ricorrenti di aziende ed Enti vittime dei criminali. E’ proprio questo il problema che attanaglia attualmente la comunità informatica in Italia, forte anche dei primi contratti assicurativi che si stanno stipulando dinanzi all’insorgenza di attacchi informatici in copertura ai diversi disservizi che ne possono sorgere, e cioè la capacità di reazione quanto più tempestiva agli attacchi ransomware, malware o di negazione del servizio, che possa rendere minimi i disagi nei confronti degli utenti che non sono solo i consumatori della manifattura italiana o industriale, ma pazienti o correntisti che necessitano dei servizi di vitale importanza. Dalle righe di Matrice Digitale, Roberto Beneduci di CoreTech ha chiesto ad ACN ed a CSIRT di condividere metodi di reazione e soluzioni sulla base di casi già successi.
Che fine fanno i dati non venduti?
Quello che dovrebbe far discutere su questa vicenda è anche un aspetto che nasconde un teoria non confermata, ma che potrebbe rappresentare un’evenienza visto il periodo storico che la transizione digitale sta vivendo.
I dati che vengono trafugati dai criminali informatici e non pagati con i riscatti, da chi vengono acquistati?
Sapere da chi non è certo, ma si può immaginare che possano essere appetibili non solo ai call center criminali come abbiamo visto, ma anche ad agenzie governative che però hanno interesse più negli attacchi persistenti e non negli attacchi ransomware di cui l’Italia è piena. A maggior ragione che, pur essendoci un nesso tra criminalità informatica ed attività di Governo , il riscatto non è sicuramente l’attacco preferito da chi ha bisogno o di distruggere un sistema informatico, ed è qui che nasce ovviamente il malware di tipo wiper, oppure c’è chi, come la Corea del Nord, si è specializzato nell’hacking delle blockchain di criptovalute ottenendo con minor sforzo una maggiore resa che negli ultimi due anni si è quantificata in più di un miliardo di dollari. Resta ancora da scoprire invece se i dati trafugati siano venduti su altri mercati e possano essere utilizzati dagli acquirenti per addestrare dei motori di intelligenza artificiale non tracciati dal mercato oppure addirittura quelli ben più noti.
Quest’ultima considerazione potrebbe essere una congettura o forse no.
Chi ha coraggio e certezze per escluderla del tutto?
Inchieste
Papa Francesco sarà al G7 e l’Italia festeggia il DDL AI
Tempo di lettura: 6 minuti. Papa Francesco partecipa al G7, focalizzato su etica e IA e il Parlamento discute il DDL AI con Meloni che promuove l’IA umanistica.

Giorgia Meloni, presidente del Consiglio, ha recentemente annunciato l’eccezionale partecipazione di Papa Francesco alla sessione del G7 dedicata all’intelligenza artificiale con in tasta il DDL sul tema. Questo evento sottolinea l’importanza crescente delle questioni etiche e umanistiche connesse allo sviluppo tecnologico.
Un impegno umanistico nell’era digitale
Durante la presidenza italiana del G7, si discuterà ampiamente su come l’intelligenza artificiale possa essere guidata da principi etici che pongono l’umanità al centro. Meloni ha enfatizzato che l’intelligenza artificiale rappresenta la più grande sfida antropologica dei nostri tempi, portando con sé notevoli opportunità ma anche rischi significativi.
La premier ha citato l’esempio della “Rome Call for AI Ethics” del 2022, una iniziativa avviata dalla Santa Sede per promuovere un approccio etico allo sviluppo degli algoritmi, un concetto noto come algoretica. L’obiettivo è sviluppare una governance dell’IA che rimanga sempre centrata sull’essere umano.
L’intervento di Papa Francesco al G7 sarà cruciale per rafforzare questa visione, offrendo una prospettiva che combina tradizione e innovazione nell’affrontare le sfide poste dall’IA alla società contemporanea.
Intelligenza Artificiale: innovazioni legislative in Italia con il DDL
L’Italia si posiziona all’avanguardia nel panorama europeo con l’approvazione di un nuovo disegno di legge sull’intelligenza artificiale. Questa legislazione pionieristica mira a promuovere un utilizzo etico e responsabile dell’IA, con un forte accento sulla protezione dei diritti fondamentali e sull’inclusione sociale.
Differenza tra Disegno di Legge e Decreto Legge
Prima di procedere, è doveroso spiegare la differenza tra un “DDL” (Disegno di Legge) e un “DL” (Decreto Legge) e che riguarda principalmente il processo legislativo e la loro natura giuridica all’interno del sistema legale italiano. Ecco i dettagli chiave:
Disegno di Legge (DDL)
- Definizione: Un DDL è una proposta legislativa elaborata e presentata al Parlamento per la discussione e l’approvazione. Può essere presentata da membri del Parlamento o dal Governo.
- Processo: Dopo essere presentato, il DDL segue un processo di esame approfondito che include discussioni, emendamenti e votazioni sia in commissione che in aula nelle due Camere del Parlamento (Camera dei Deputati e Senato della Repubblica). Questo processo può essere lungo e richiede l’approvazione finale di entrambe le Camere.
- Natura: Il DDL è di natura ordinaria, significando che non ha effetto immediato e deve seguire il normale iter parlamentare prima di diventare legge.
Decreto Legge (DL)
- Definizione: Un DL è uno strumento legislativo che il Governo può adottare in casi straordinari di necessità e urgenza. Questo decreto ha forza di legge dal momento della sua pubblicazione, ma è temporaneo.
- Processo: Un DL deve essere convertito in legge dal Parlamento entro 60 giorni dalla sua pubblicazione, attraverso un processo che può includere modifiche e approvazioni. Se non convertito, perde efficacia retroattivamente.
- Natura: Il DL ha un’immediata efficacia legale ma è temporaneo e condizionato alla sua conversione in legge ordinaria, che stabilizza le disposizioni contenute nel decreto.
Confronto e uso
- Velocità ed Efficienza: Il DL è molto più rapido nel rispondere a situazioni di emergenza, dato che entra in vigore immediatamente. Tuttavia, questa rapidità viene bilanciata dalla necessità di una successiva conferma parlamentare.
- Stabilità e Riflessione: Il DDL segue un processo più riflessivo e può essere soggetto a più ampie discussioni e revisioni, il che può contribuire a una legislazione più ponderata e dettagliata.
Il DL è utilizzato per situazioni urgenti che richiedono una risposta legislativa immediata, mentre il DDL è il mezzo standard per la creazione di nuove leggi, offrendo più opportunità per l’esame e la discussione parlamentare.
Focus sui Principi Generali e innovazioni
Il disegno di legge definisce norme precise per la ricerca, lo sviluppo, e l’implementazione dell’IA, assicurando che ogni applicazione tecnologica rispetti la dignità umana e le libertà fondamentali, come stabilito dalla Costituzione italiana e dal diritto dell’Unione Europea. Tra i principi chiave, spicca l’impegno verso la trasparenza, la sicurezza dei dati, e l’equità, evitando discriminazioni e promuovendo la parità di genere.
Uno degli aspetti più rilevanti è l’introduzione di un quadro normativo per garantire che l’IA non sostituisca ma supporti il processo decisionale umano, mantenendo l’uomo al centro dell’innovazione tecnologica. In particolare, il disegno di legge enfatizza l’importanza della cybersicurezza e impone rigidi controlli di sicurezza per proteggere l’integrità dei sistemi di IA.
La legge stabilisce principi chiave per l’adozione e l’applicazione dell’IA in Italia, focalizzandosi su trasparenza, proporzionalità, sicurezza e non discriminazione. Viene data particolare attenzione al rispetto dei diritti umani e alla promozione di una IA “antropocentrica”, ossia che metta al centro le esigenze e il benessere dell’individuo.
Settori di impatto e disposizioni specifiche
La legislazione tocca vari settori, dalla sanità al lavoro, dalla difesa alla sicurezza nazionale, delineando norme specifiche per ciascuno:
Sanità
L’IA dovrebbe migliorare il sistema sanitario senza discriminare l’accesso alle cure. Si promuove l’uso dell’IA per assistere la decisione medica, ma la responsabilità finale rimane sempre nelle mani dei professionisti. L’impiego dell’intelligenza artificiale nel settore sanitario, come delineato nella nuova legislazione italiana, è concepito per migliorare l’efficacia e l’efficienza dei servizi sanitari, pur salvaguardando i diritti e la dignità dei pazienti. La legge impone che l’introduzione di sistemi di IA nel sistema sanitario avvenga senza discriminare l’accesso alle cure e che le decisioni mediche rimangano prerogativa del personale medico, sebbene assistito dalla tecnologia. È previsto inoltre che i pazienti siano adeguatamente informati sull’uso delle tecnologie di intelligenza artificiale, ricevendo dettagli sui benefici diagnostici e terapeutici previsti e sulla logica decisionale impiegata.
Implicazioni della Legge sulla Sicurezza e Difesa Nazionale:
Le applicazioni di IA per scopi di sicurezza nazionale devono avvenire nel rispetto dei diritti costituzionali, con una regolamentazione specifica che esclude queste attività dall’ambito di applicazione della legge generale. La legge tratta specificamente l’applicazione dell’intelligenza artificiale per scopi di sicurezza e difesa nazionale, stabilendo che queste attività siano escluse dall’ambito di applicazione delle norme generali sulla regolamentazione dell’IA. Tuttavia, è chiaro che tali attività devono comunque svolgersi nel rispetto dei diritti fondamentali e delle libertà costituzionali. Si prevede che l’uso dell’IA per la sicurezza nazionale sia regolato da normative specifiche, garantendo la conformità ai principi di correttezza, sicurezza e trasparenza, e imponendo controlli rigorosi per prevenire abusi.
Lavoro
Viene regolato l’utilizzo dell’IA per migliorare le condizioni lavorative e la produttività, garantendo trasparenza e sicurezza nell’uso dei dati dei lavoratori. L’adozione dell’intelligenza artificiale nel settore lavorativo, secondo la nuova normativa italiana, mira a migliorare le condizioni di lavoro e accrescere la produttività mantenendo al centro la sicurezza e la trasparenza. Gli impieghi di sistemi di IA devono avvenire nel rispetto della dignità umana e della riservatezza dei dati personali. I datori di lavoro sono obbligati a informare i lavoratori sull’utilizzo dell’IA, delineando chiaramente gli scopi e le modalità di impiego. La legge pone un’enfasi particolare sulla non discriminazione, assicurando che l’IA non crei disparità tra i lavoratori basate su sesso, età, origine etnica, orientamento sessuale, o qualsiasi altra condizione personale.
Iniziative per l’inclusione e la formazione
Significative sono le disposizioni per garantire l’accesso all’IA da parte delle persone con disabilità, assicurando pari opportunità e piena partecipazione. Viene inoltre data importanza alla formazione e all’alfabetizzazione digitale in tutti i livelli educativi per preparare i cittadini a interagire con le nuove tecnologie.
Il disegno di legge promuove attivamente la formazione e l’alfabetizzazione digitale come componenti fondamentali per l’integrazione dell’intelligenza artificiale nella società. Questo include l’implementazione di programmi di formazione sia nei curricoli scolastici che nei contesti professionali, al fine di preparare studenti e lavoratori a interagire efficacemente e eticamente con le tecnologie avanzate. Si prevede inoltre che gli ordini professionali introducano percorsi specifici per i propri iscritti, affinché possano acquisire le competenze necessarie per utilizzare l’IA in modo sicuro e responsabile nel rispetto delle normative vigenti.
Tutela della Privacy e della Proprietà Intellettuale
La legge enfatizza la protezione dei dati personali e introduce regole per garantire che i contenuti generati o manipolati tramite IA siano chiaramente identificati, proteggendo così l’integrità informativa e i diritti d’autore. La nuova legislazione italiana stabilisce criteri rigorosi per la protezione della privacy degli individui nell’ambito dell’utilizzo dell’intelligenza artificiale. Si impone che ogni applicazione di IA che tratti dati personali debba avvenire in modo lecito, corretto e trasparente, conformemente alle normative dell’Unione Europea. La legge richiede inoltre che le informazioni relative al trattamento dei dati personali siano comunicate agli utenti in un linguaggio chiaro e accessibile, garantendo loro la possibilità di comprendere e, se necessario, opporsi al trattamento dei propri dati. Viene enfatizzata la necessità di una cybersicurezza efficace in tutte le fasi del ciclo di vita dei sistemi di IA, per prevenire abusi o manipolazioni.
Per quanto riguarda la proprietà intellettuale, il disegno di legge introduce misure specifiche per assicurare che le opere generate attraverso l’intelligenza artificiale siano correttamente attribuite e tutelate sotto il diritto d’autore. Viene riconosciuto il diritto d’autore per le opere create con l’ausilio dell’IA, purché vi sia un significativo contributo umano che sia creativo, rilevante e dimostrabile. Inoltre, la legge prevede che ogni contenuto generato o modificato significativamente da sistemi di IA debba essere chiaramente identificato come tale, per mantenere la trasparenza e prevenire la diffusione di informazioni ingannevoli o falsificate.
Libertà di Informazione e dati personali
L’articolo 4 del DDL stabilisce che l’uso dell’IA nel settore dell’informazione deve avvenire senza compromettere la libertà e il pluralismo dei media, mantenendo l’obiettività e l’imparzialità delle informazioni. È essenziale che l’intelligenza artificiale non distorca la veridicità e la completezza dell’informazione a causa di pregiudizi intrinseci nei modelli di apprendimento automatico.
Trasparenza e correttezza nel Trattamento dei Dati
Viene enfatizzato il trattamento lecito, corretto e trasparente dei dati personali, in linea con il GDPR. Il DDL richiede che le informazioni sul trattamento dei dati siano fornite in modo chiaro e comprensibile, consentendo agli utenti di avere pieno controllo sulla gestione dei propri dati.
Consapevolezza e controllo per i minori
Una specifica attenzione è rivolta alla protezione dei minori nell’accesso alle tecnologie AI. I minori di quattordici anni necessitano del consenso dei genitori per l’utilizzo di tali tecnologie, mentre quelli tra i quattordici e i diciotto anni possono dare il consenso autonomamente, purché le informazioni siano chiare e accessibili.
Governance e collaborazione tra Agenzie
Il DDL promuove un approccio di governance “duale”, coinvolgendo l’Agenzia per la Cybersicurezza Nazionale (ACN) e l’Agenzia per l’Italia Digitale (AgID) per assicurare che l’applicazione delle tecnologie AI sia conforme sia alle normative nazionali che a quelle dell’Unione Europea. Queste agenzie lavoreranno insieme per stabilire un quadro regolatorio solido che promuova la sicurezza senza soffocare l’innovazione.
Leggi il DDL sull’Intelligenza Artificiale




Google ripara la quinta Vulnerabilità Zero-Day di Chrome nel 2024
Tempo di lettura: 2 minuti. Google ha rilasciato un aggiornamento per Chrome, correggendo la vulnerabilità zero-day CVE-2024-4671, marcata come attivamente...


Disastro Dell: violazione dati di 49 Milioni di clienti
Tempo di lettura: 2 minuti. Dell annuncia una violazione dei dati che ha esposto nomi e indirizzi di 49 milioni...


Nuovo attacco “Pathfinder” alle CPU Intel: è il nuovo Spectre?
Tempo di lettura: 2 minuti. Pathfinder mira ai CPU Intel, in grado di recuperare chiavi di crittografia e perdere dati...


Nuovo attacco “TunnelVision” espone il traffico VPN
Tempo di lettura: 2 minuti. Scopri come il nuovo attacco TunnelVision utilizza server DHCP malevoli per esporre il traffico VPN,...


Esplosione di malware JavaScript nei Siti con plugin LiteSpeed Cache
Tempo di lettura: 2 minuti. Scopri l'impennata di malware JavaScript che colpisce i siti con versioni vulnerabili del plugin LiteSpeed...


Ransomware in Italia: come cambia la percezione del fenomeno nell’IT
Tempo di lettura: 5 minuti. I ransowmare sembrano essere passati di moda per il poco clamore suscitato in un paese...


NSA, FBI e Dipartimento di Stato affrontano le minacce informatiche nordcoreane
Tempo di lettura: 2 minuti. NSA, FBI e Stato emettono un avviso sulle minacce nordcoreane, esortando politiche DMARC più forti...


Cisa e Aruba minacciate per vulnerabilità ICS e di rete
Tempo di lettura: 2 minuti. CISA e FBI evidenziano nuove minacce alla sicurezza dei sistemi di controllo industriale e delle...
Apple, Regno Unito vuole più sicurezza informatica e l’Europa indica iPadOS Gatekeeper
Tempo di lettura: 2 minuti. Apple, nuove sfide normative con l'introduzione del PSTI Act nel Regno Unito e la designazione...


ACN: tutto quello che c’è da sapere sulla relazione annuale 2023
Tempo di lettura: 9 minuti. L'ACN presenta la relazione annuale sulle attività della cybersecurity in Italia nel 2023 ed i...


BogusBazaar falsi e-commerce usati per una truffa da 50 milioni
Tempo di lettura: 2 minuti. Oltre 850,000 persone sono state ingannate da una rete di 75,000 falsi negozi online, con...


Truffatori austriaci scappano dagli investitori, ma non dalla legge
Tempo di lettura: 2 minuti. Le forze dell'ordine hanno smascherato e arrestato un gruppo di truffatori austriaci dietro una frode...


Truffa dei buoni SHEIN da 300 euro, scopri come proteggerti
Tempo di lettura: < 1 minuto. La truffa dei buoni SHEIN da 300 euro sta facendo nuovamente vittime in Italia,...


USA interviene per recuperare 2,3 Milioni dai “Pig Butchers” su Binance
Tempo di lettura: 2 minuti. Il Dipartimento di Giustizia degli USA interviene per recuperare 2,3 milioni di dollari in criptovalute...


Truffa dimarcoutletfirenze.com: merce contraffatta e diversi dalle prenotazioni
Tempo di lettura: 2 minuti. La segnalazione alla redazione di dimarcoutletfirenze.com si è rivelata puntuale perchè dalle analisi svolte è...


No, la SEC non ha approvato ETF del Bitcoin. Ecco perchè
Tempo di lettura: 3 minuti. Il mondo delle criptovalute ha recentemente assistito a un evento senza precedenti: l’account Twitter ufficiale...


Europol mostra gli schemi di fronde online nel suo rapporto
Tempo di lettura: 2 minuti. Europol’s spotlight report on online fraud evidenzia che i sistemi di frode online rappresentano una grave...


Polizia Postale: attenzione alla truffa dei biglietti ferroviari falsi
Tempo di lettura: < 1 minuto. Gli investigatori della Polizia Postale hanno recentemente individuato una nuova truffa online che prende...

App Falsa di Ledger Ruba Criptovalute
Tempo di lettura: 2 minuti. Un'app Ledger Live falsa nel Microsoft Store ha rubato 768.000 dollari in criptovalute, sollevando dubbi...


Google: pubblicità malevole che indirizzano a falso sito di Keepass
Tempo di lettura: 2 minuti. Google ospita una pubblicità malevola che indirizza gli utenti a un falso sito di Keepass,...


Honor 200 Pro: rivelazioni e render mostrano nuove caratteristiche
Tempo di lettura: 2 minuti. Honor 200 Pro si svela con nuovi render: design premium, tripla fotocamera con zoom 50X,...


One UI 6.1 per Galaxy Z Flip 4 è disponibile in Europa
Tempo di lettura: 2 minuti. Il Galaxy Z Flip 4 riceve l'aggiornamento One UI 6.1 in Europa, portando miglioramenti AI...


Moto G Stylus 5G (2024): innovazioni e caratteristiche uniche
Tempo di lettura: 2 minuti. Scopri il nuovo Moto G Stylus 5G (2024) con uno stilo integrato, fotocamere avanzate e...


Motorola Razr 50 5G: prezzo e opzioni per il mercato europeo
Tempo di lettura: 2 minuti. Motorola lancia il Razr 50 5G in Europa a 899 euro, disponibile in colori Sand...


Microsoft lancia il suo negozio di giochi mobile a luglio
Tempo di lettura: 2 minuti. Microsoft lancerà il suo negozio di giochi mobile a luglio, offrendo titoli come Candy Crush...


LibreOffice 7.6.7: disponibile l’ultimo aggiornamento
Tempo di lettura: < 1 minuto. LibreOffice 7.6.7 è stato rilasciato come ultimo aggiornamento della serie, con un invito agli...


Tesla Optimus, il nuovo video visto con attenzione
Tempo di lettura: < 1 minuto. Tesla pubblica su Twitter/X un nuovo video del proprio automa "Optimus" mentre smista delle...


OpenAI pronta a lanciare un concorrente di Google Search
Tempo di lettura: 2 minuti. Si attende l'annuncio ufficiale del nuovo motore di ricerca Web di OpenAI


Lo spot iPad e la pressa maledetta, le scuse di Apple
Tempo di lettura: 2 minuti. Lo spot Apple per il lancio del nuovo iPad Pro fa indignare la Rete


OpenAI sfida Google con un nuovo Motore di Ricerca AI
Tempo di lettura: 2 minuti. OpenAI sta per lanciare un motore di ricerca AI il giorno prima del Google I/O,...
 Inchieste2 settimane fa
Inchieste2 settimane faPapa Francesco sarà al G7 e l’Italia festeggia il DDL AI
- Cyber Security2 settimane fa
ACN: tutto quello che c’è da sapere sulla relazione annuale 2023
- Economia2 settimane fa
Apple, Regno Unito vuole più sicurezza informatica e l’Europa indica iPadOS Gatekeeper
- Editoriali1 settimana fa
Chip e smartphone cinesi ci avvisano del declino Occidentale
- Inchieste6 giorni fa
Ransomware in Italia: come cambia la percezione del fenomeno nell’IT
- Economia1 settimana fa
Internet via satellite: progetto europeo IRIS² in grande difficoltà
- Economia1 settimana fa
Apple: cala il fatturato, preoccupazioni per il DOJ e speranze dal nuovo iPad
- Editoriali4 giorni fa
Anche su Giovanna Pedretti avevamo ragione









